More Data Operations in R
Ani Ruhil
Agenda
This week we continue to learn how to organize and clean messy data.
package of choice here is
{tidyr}can reshape data
long-to-wideandwide-to-longcan
separateandunitecolumns
separate()
You will, at times, end up with columns that contain multiple pieces of information, all mashed up into some alphanumeric string or sequence of numbers. separate() allows us to split this mashed up column into specific pieces. For example, here are some data from the Census Bureau:
library(tidyverse)read.csv( "https://www2.census.gov/programs-surveys/popest/datasets/2010-2018/metro/totals/cbsa-est2018-alldata.csv" ) -> cbsacbsa %>% select(NAME) %>% glimpse()## Observations: 2,789## Variables: 1## $ NAME [3m[90m<fct>[39m[23m "Abilene, TX", "Callahan County, TX", "Jones County, TX", "Taylor…This data-set contains population estimates for CBSAs -- core-based statistical areas. What are these?
Metropolitan and Micropolitan Statistical Areas are collectively referred to as Core-Based Statistical Areas. Metropolitan statistical areas have at least one urbanized area of 50,000 or more population, plus adjacent territory that has a high degree of social and economic integration with the core as measured by commuting ties. Micropolitan statistical areas are a new set of statistical areas that have at least one urban cluster of at least 10,000 but less than 50,000 population, plus adjacent territory that has a high degree of social and economic integration with the core as measured by commuting ties. Metropolitan and micropolitan statistical areas are defined in terms of whole counties or county equivalents, including the six New England states. As of June 6, 2003, there are 362 metropolitan statistical areas and 560 micropolitan statistical areas in the United States. Source
Look at the column called NAME ... it combines the state's name (abbreviated) and the name of the area, "Abilene, TX", "Callahan County, TX", etc
We need to split this NAME column into two pieces -- placename ("Abilene", "Callahan County", etc) and stateabb ("TX", "TX", etc.)
We do this below, with the separation occurring where a "," is seen in NAME
cbsa %>% separate( col = NAME, into = c("placename", "stateabb"), sep = ",", remove = FALSE ) -> cbsa cbsa %>% select(NAME, placename, stateabb) %>% head()## NAME placename stateabb## 1 Abilene, TX Abilene TX## 2 Callahan County, TX Callahan County TX## 3 Jones County, TX Jones County TX## 4 Taylor County, TX Taylor County TX## 5 Akron, OH Akron OH## 6 Portage County, OH Portage County OHHere is what each piece of code is doing:
| code | what it does ... |
|---|---|
| col = | identifies the column to be separated |
| into = | creates the names for the new columns that will result |
| sep = | indicates where the separation should occur |
| remove = | indicates whether the column to be separated should be removed from the data-set or retained once the new columns have been created. Setting it equal to FALSE will keep the original column, TRUE will remove it. |
What if the column to be separated was made up of numbers rather than text?
Take the STCOU column that contains FIPS codes
First two digits = the state; next three digits = the area. Ohio's FIPS code is, for instance, 39, and Portage County's FIPS code is 133
We create two new columns, one with the state FIPS code (stfips) and the second with the county FIPS code (coufips)
This time setting sep = 2 because we want the separation to happen after the second digit.
cbsa %>% separate( col = STCOU, into = c("stfips", "coufips"), sep = 2, remove = FALSE ) -> cbsacbsa %>% select(STCOU, stfips, coufips) %>% head()## STCOU stfips coufips## 1 NA <NA> <NA>## 2 48059 48 059## 3 48253 48 253## 4 48441 48 441## 5 NA <NA> <NA>## 6 39133 39 133unite()
This is the opposite of separate() -- two or more columns are united into ONE column. For example, take the file I am reading in as coudf.
This file has similar content to what we read in for the CBSAs but this one has data for counties and states.
read_csv( "https://www2.census.gov/programs-surveys/popest/datasets/2010-2018/counties/totals/co-est2018-alldata.csv" ) -> coudfFilter to retain rows only for counties. I am doing this with filter(COUNTY != "000") because the state rows are the ones with COUNTY == "000".
coudf %>% filter(COUNTY != "000") -> coudf2coudf2 %>% select(STNAME, CTYNAME) %>% glimpse()## Observations: 3,193## Variables: 2## $ STNAME <chr> "Alabama", "Alabama", "Alabama", "Alabama", "Alabama", "Alabam…## $ CTYNAME <chr> "Alabama", "Autauga County", "Baldwin County", "Barbour County…Now I want to combine the county name (CTYNAME) and the state name (STNAME) into a single column, with the two names separated by a comma and a single white-space, i.e., by ", ".
coudf2 %>% unite( col = "countystate", c("CTYNAME", "STNAME"), sep = ", ", remove = FALSE ) -> coudf2coudf2 %>% select(CTYNAME, STNAME, countystate) %>% head()## # A tibble: 6 x 3## CTYNAME STNAME countystate ## <chr> <chr> <chr> ## 1 Autauga County Alabama Autauga County, Alabama## 2 Baldwin County Alabama Baldwin County, Alabama## 3 Barbour County Alabama Barbour County, Alabama## 4 Bibb County Alabama Bibb County, Alabama ## 5 Blount County Alabama Blount County, Alabama ## 6 Bullock County Alabama Bullock County, Alabamahere is what each piece of code is doing ...
| code | what it does ... |
|---|---|
| col = | identifies the new column to be created |
| c("..") | identifies the columns to be combined, as in c("column1", "column2", "column3") |
| sep = | indicates if we want the merged elements to be separated in some manner. Here we are using ", " to separate with a comma followed by a single white-space. But we could have used any separator or no separator at all |
| remove = | indicates if we want the original columns deleted (TRUE) or not (FALSE) |
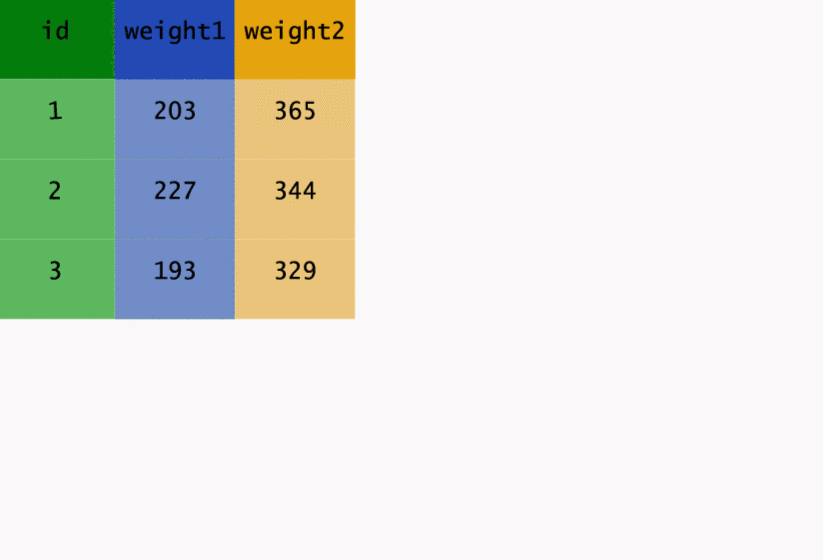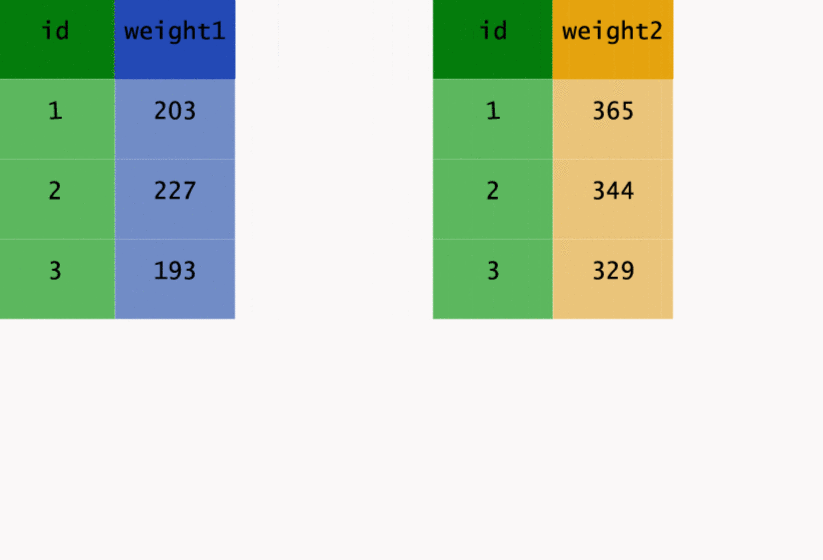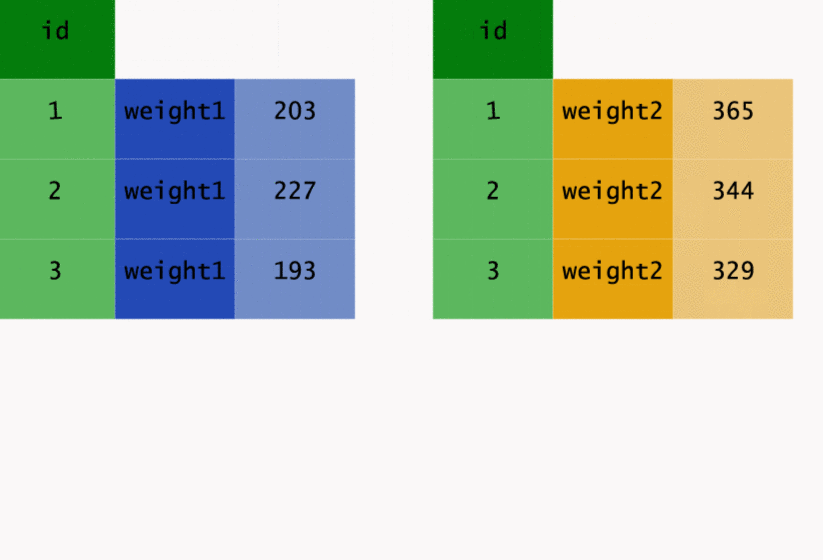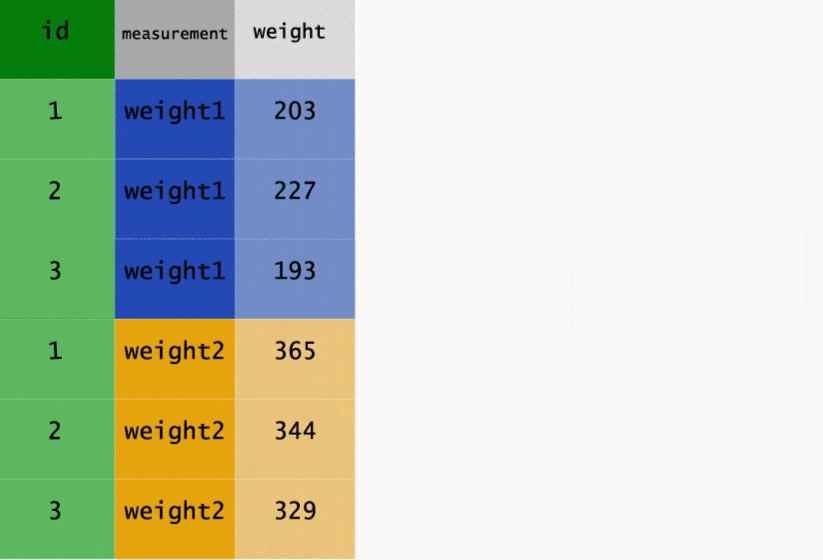
If I look at the original CBSA file cbsa, I see that it has been setup very oddly.
In particular, starting with column 6 we have a jumble of information ...
- CENSUS2010POP, ESTIMATESBASE2010, POPESTIMATE2010 all have the population total for 2010.
- POPESTIMATE2011 through POPESTIMATE2018 are the population totals for 2011-2018
- NPOPCHG_20XY give us net population change for 2010-2018
- BIRTHS20XY give us the number of births for 2010-2018
- DEATHS20XY give us the number of deaths for 2010-2018
- NATURALINC20XY gives us the natural increase = births - deaths for 2010-2018
- INTERNATIONALMIG20XY gives us international immigrant totals for for 2010-2018
- DOMESTICMIG20XY gives us domestic migrant totals for 2010-2018
- NETMIG20XY give us net migration totals for 2010-2018
- RESIDUAL20XY gives us some small numbers left over after adding and subtracting the
Let us keep only a few columns to see what the current layout looks like.
read_csv( "https://www2.census.gov/programs-surveys/popest/datasets/2010-2018/metro/totals/cbsa-est2018-alldata.csv" ) -> cbsacbsa %>% select(c(4, 8:16)) -> cbsa01cbsa01 %>% head()## # A tibble: 6 x 10## NAME POPESTIMATE2010 POPESTIMATE2011 POPESTIMATE2012 POPESTIMATE2013## <chr> <dbl> <dbl> <dbl> <dbl>## 1 Abil… 165583 166616 167447 167472## 2 Call… 13513 13511 13488 13501## 3 Jone… 20237 20266 19870 20034## 4 Tayl… 131833 132839 134089 133937## 5 Akro… 703035 703123 702080 703625## 6 Port… 161389 161857 161375 161691## # … with 5 more variables: POPESTIMATE2014 <dbl>, POPESTIMATE2015 <dbl>,## # POPESTIMATE2016 <dbl>, POPESTIMATE2017 <dbl>, POPESTIMATE2018 <dbl>Wide-to-Long with pivot_longer()
Why did they not setup the data in such a way that it had the following structure? This would make a lot more sense rather than having each year be a column all its own.
| NAME | YEAR | POPULATION |
|---|---|---|
| Abilene, TX | 2010 | 165583 |
| Abilene, TX | 2011 | 166616 |
| Abilene, TX | 2012 | 167447 |
| .... | .... | .... |
| Callahan County, TX | 2010 | 13513 |
| Callahan County, TX | 2011 | 13511 |
| Callahan County, TX | 2012 | 13488 |
| .... | .... | .... |
Well, we can easily create the proper structure of the data-set, starting as shown below ...
cbsa01 %>% group_by(NAME) %>% pivot_longer( names_to = "variable", values_to = "POPULATION", 2:10 ) -> cbsa01.longcbsa01.long %>% head()## # A tibble: 6 x 3## # Groups: NAME [1]## NAME variable POPULATION## <chr> <chr> <dbl>## 1 Abilene, TX POPESTIMATE2010 165583## 2 Abilene, TX POPESTIMATE2011 166616## 3 Abilene, TX POPESTIMATE2012 167447## 4 Abilene, TX POPESTIMATE2013 167472## 5 Abilene, TX POPESTIMATE2014 168355## 6 Abilene, TX POPESTIMATE2015 169704This is what each piece of code does ...
| code | what it does ... |
|---|---|
| names_to = | identifies the name of the new column that will be created |
| values_to = | identifies the name of the new column in which values will be stored |
| 2:10 | identifies the columns that will be pivoted from wide to long |
| group_by() | holds unique combinations of whatever column names you put in group_by() fixed while it pivots the other columns |
I still need to clean up the variable column so that it only shows the four-digit year rather than POPESTIMATE2010, and so on. Let us do this next.
cbsa01.long %>% separate( col = variable, into = c("todiscard", "toyear"), sep = 11, remove = TRUE) -> cbsa01.long2cbsa01.long2 %>% mutate(YEAR = as.numeric(toyear)) %>% select(c(NAME, YEAR, POPULATION)) -> cbsa01.long3cbsa01.long3 %>% head()## # A tibble: 6 x 3## # Groups: NAME [1]## NAME YEAR POPULATION## <chr> <dbl> <dbl>## 1 Abilene, TX 2010 165583## 2 Abilene, TX 2011 166616## 3 Abilene, TX 2012 167447## 4 Abilene, TX 2013 167472## 5 Abilene, TX 2014 168355## 6 Abilene, TX 2015 169704Long-to-wide with pivot_wider()
Say the data-set was perhaps the one shown below. This data-set comes from the 2017 American Community Survey and along with state FIPS codes (geoid) and state name (NAME) it has data on income = median yearly income, rent = median monthly rent, and moe = the margin of error at the 90% confidence level.
us_rent_income %>% head()## # A tibble: 6 x 5## GEOID NAME variable estimate moe## <chr> <chr> <chr> <dbl> <dbl>## 1 01 Alabama income 24476 136## 2 01 Alabama rent 747 3## 3 02 Alaska income 32940 508## 4 02 Alaska rent 1200 13## 5 04 Arizona income 27517 148## 6 04 Arizona rent 972 4Notice here the setup looks weird because two different variables have been combined in a single column. Instead, the data-set should have been setup as follows:
| GEOID | NAME | income | rent | moe_income | moe_rent |
|---|---|---|---|---|---|
| 01 | Alabama | 24476 | 747 | 136 | 3 |
| 02 | Alaska | 32940 | 1200 | 508 | 13 |
| 03 | Arizona | 27517 | 972 | 148 | 4 |
| ... | ... | ... | ... | ... | ... |
Well, this can be achieved with the pivot_wider() function that takes from the "long" format to the "wide" format.
us_rent_income %>% group_by(GEOID, NAME) %>% pivot_wider( names_from = variable, values_from = c(estimate, moe) ) -> usri.wideusri.wide %>% head()## # A tibble: 6 x 6## # Groups: GEOID, NAME [6]## GEOID NAME estimate_income estimate_rent moe_income moe_rent## <chr> <chr> <dbl> <dbl> <dbl> <dbl>## 1 01 Alabama 24476 747 136 3## 2 02 Alaska 32940 1200 508 13## 3 04 Arizona 27517 972 148 4## 4 05 Arkansas 23789 709 165 5## 5 06 California 29454 1358 109 3## 6 08 Colorado 32401 1125 109 5Here is what each piece of code does ...
| code | what it does ... |
|---|---|
| names_from = | identifies the column from which unique values will be taken to create the names of the new columns that will result |
| values_from = | identifies the column(s) from which the values should be assigned to the new columns that will result |
| group_by() | holds unique value combinations of whatever column names you put in group_by() fixed while it pivots the rows to new columns |
The example that follows is a tricky one so be careful!!
With the cbsa data we could use a combination of pivot_longer() and pivot_wider()
cbsa %>% select(3:5, 8:88) %>% group_by(NAME) %>% pivot_longer( names_to = "variable", values_to = "estimate", 4:84 ) -> cbsa.01cbsa.01 %>% head()## # A tibble: 6 x 5## # Groups: NAME [1]## STCOU NAME LSAD variable estimate## <chr> <chr> <chr> <chr> <dbl>## 1 <NA> Abilene, TX Metropolitan Statistical Area POPESTIMATE2010 165583## 2 <NA> Abilene, TX Metropolitan Statistical Area POPESTIMATE2011 166616## 3 <NA> Abilene, TX Metropolitan Statistical Area POPESTIMATE2012 167447## 4 <NA> Abilene, TX Metropolitan Statistical Area POPESTIMATE2013 167472## 5 <NA> Abilene, TX Metropolitan Statistical Area POPESTIMATE2014 168355## 6 <NA> Abilene, TX Metropolitan Statistical Area POPESTIMATE2015 169704Now I will clean up the contents of cbsa.01 so that year is a separate column.
cbsa.01 %>% separate( col = "variable", into = c("vartype", "year"), sep = "(?=[[:digit:]])", extra = "merge", remove = FALSE ) -> cbsa.02cbsa.02 %>% head()## # A tibble: 6 x 7## # Groups: NAME [1]## STCOU NAME LSAD variable vartype year estimate## <chr> <chr> <chr> <chr> <chr> <chr> <dbl>## 1 <NA> Abilene, … Metropolitan Statistic… POPESTIMATE2… POPESTIM… 2010 165583## 2 <NA> Abilene, … Metropolitan Statistic… POPESTIMATE2… POPESTIM… 2011 166616## 3 <NA> Abilene, … Metropolitan Statistic… POPESTIMATE2… POPESTIM… 2012 167447## 4 <NA> Abilene, … Metropolitan Statistic… POPESTIMATE2… POPESTIM… 2013 167472## 5 <NA> Abilene, … Metropolitan Statistic… POPESTIMATE2… POPESTIM… 2014 168355## 6 <NA> Abilene, … Metropolitan Statistic… POPESTIMATE2… POPESTIM… 2015 169704Now the final flip to wide format ...
cbsa.02 %>% select(c(2, 5:7)) %>% group_by(NAME, year) %>% pivot_wider( names_from = "vartype", values_from = "estimate" ) -> cbsa.03cbsa.03 %>% glimpse()## Observations: 25,083## Variables: 11## Groups: NAME, year [25,083]## $ NAME <chr> "Abilene, TX", "Abilene, TX", "Abilene, TX", "Abilene…## $ year <chr> "2010", "2011", "2012", "2013", "2014", "2015", "2016…## $ POPESTIMATE <list> [165583, 166616, 167447, 167472, 168355, 169704, 170…## $ NPOPCHG <list> [337, 1033, 831, 25, 883, 1349, 314, 498, 935, -33, …## $ BIRTHS <list> [540, 2295, 2358, 2390, 2382, 2417, 2379, 2427, 2381…## $ DEATHS <list> [406, 1506, 1587, 1694, 1598, 1698, 1726, 1705, 1739…## $ NATURALINC <list> [134, 789, 771, 696, 784, 719, 653, 722, 642, -29, -…## $ INTERNATIONALMIG <list> [84, 205, 516, 361, 419, 484, 388, 325, 282, 0, 4, 5…## $ DOMESTICMIG <list> [124, 54, -448, -1051, -301, 162, -723, -544, 19, -3…## $ NETMIG <list> [208, 259, 68, -690, 118, 646, -335, -219, 301, -3, …## $ RESIDUAL <list> [-5, -15, -8, 19, -19, -16, -4, -5, -8, -1, -1, -2, …