the grammar of graphics
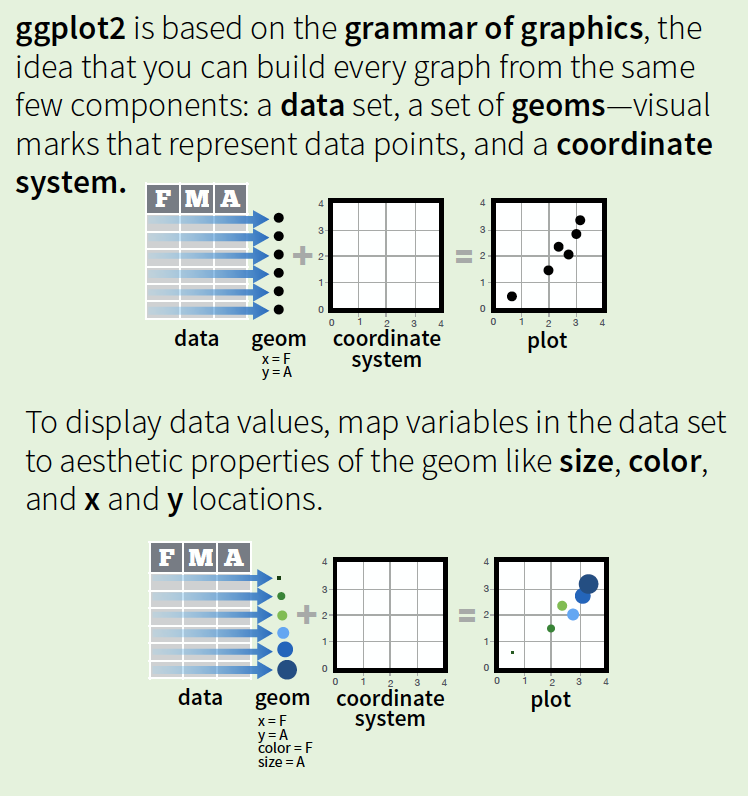
data = cleaned and mutated or summarized to give us what we'd like to visualize
geom = what kind of a visual do you want? A map, bar-chart, line-chart, scatter-plot, something else?
coordinate system = what should go on the x-axis? y-axis?
What other aesthetics should be used, border colors, fill colors, text or other annotations, plotting symbols, facet the plot to show breakouts by some attribute, something else?
load("data/multkey.merge.RData")my.df <- multkey.mergelibrary(tidyverse)ggplot(data = my.df)
The canvas is blank because we have not specified what goes on the x-axis, y-axis
That can be specified via aes ... the aesthetics
ggplot(data = my.df, aes(x = college_desc))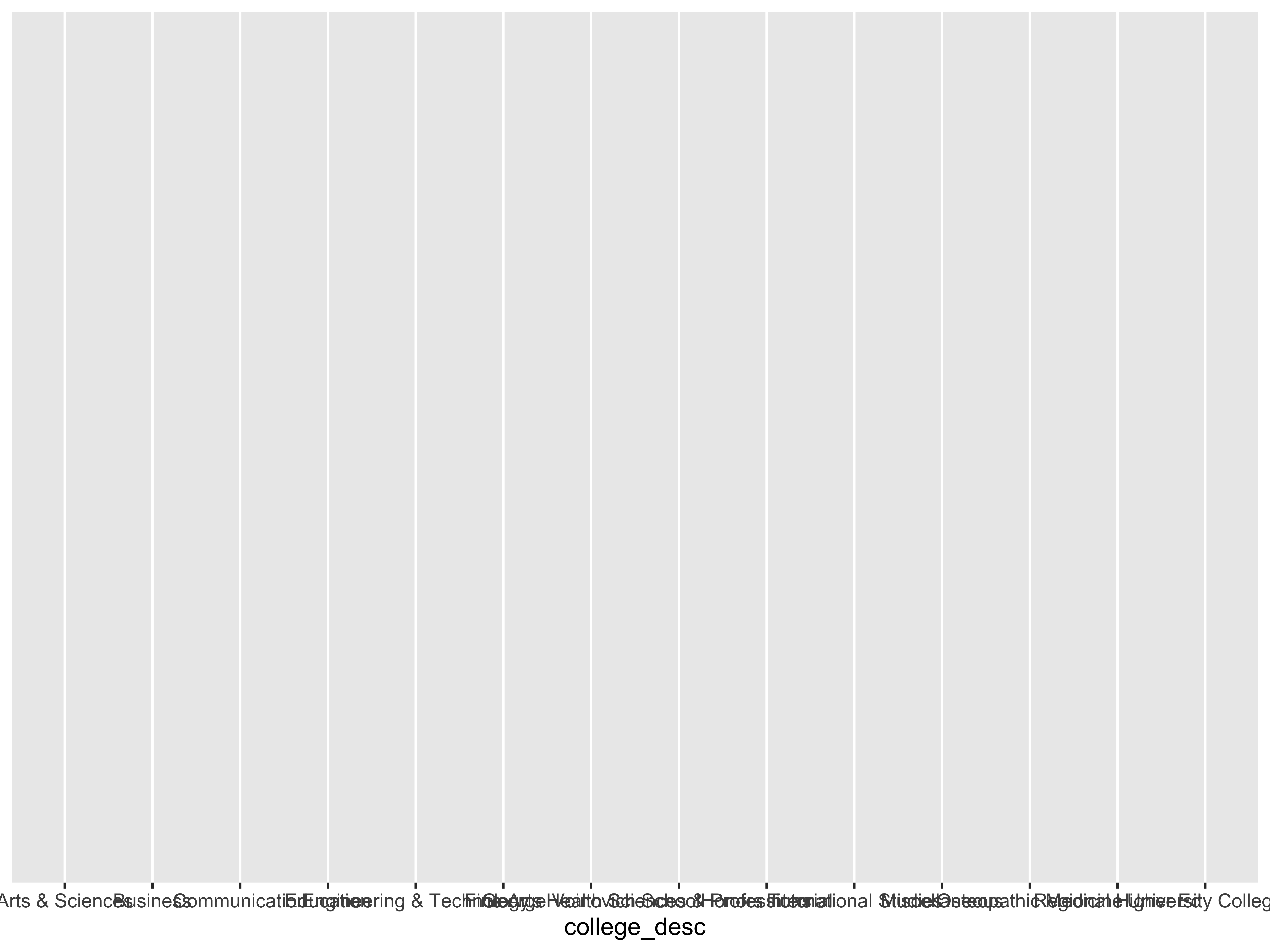
Aha! Now we see the labels on the x-axis but nothing more. Why?
Because we have not specified what type of a graphic we want ... a bar-chart perhaps?
ggplot(data = my.df, aes(x = college_desc)) + geom_bar()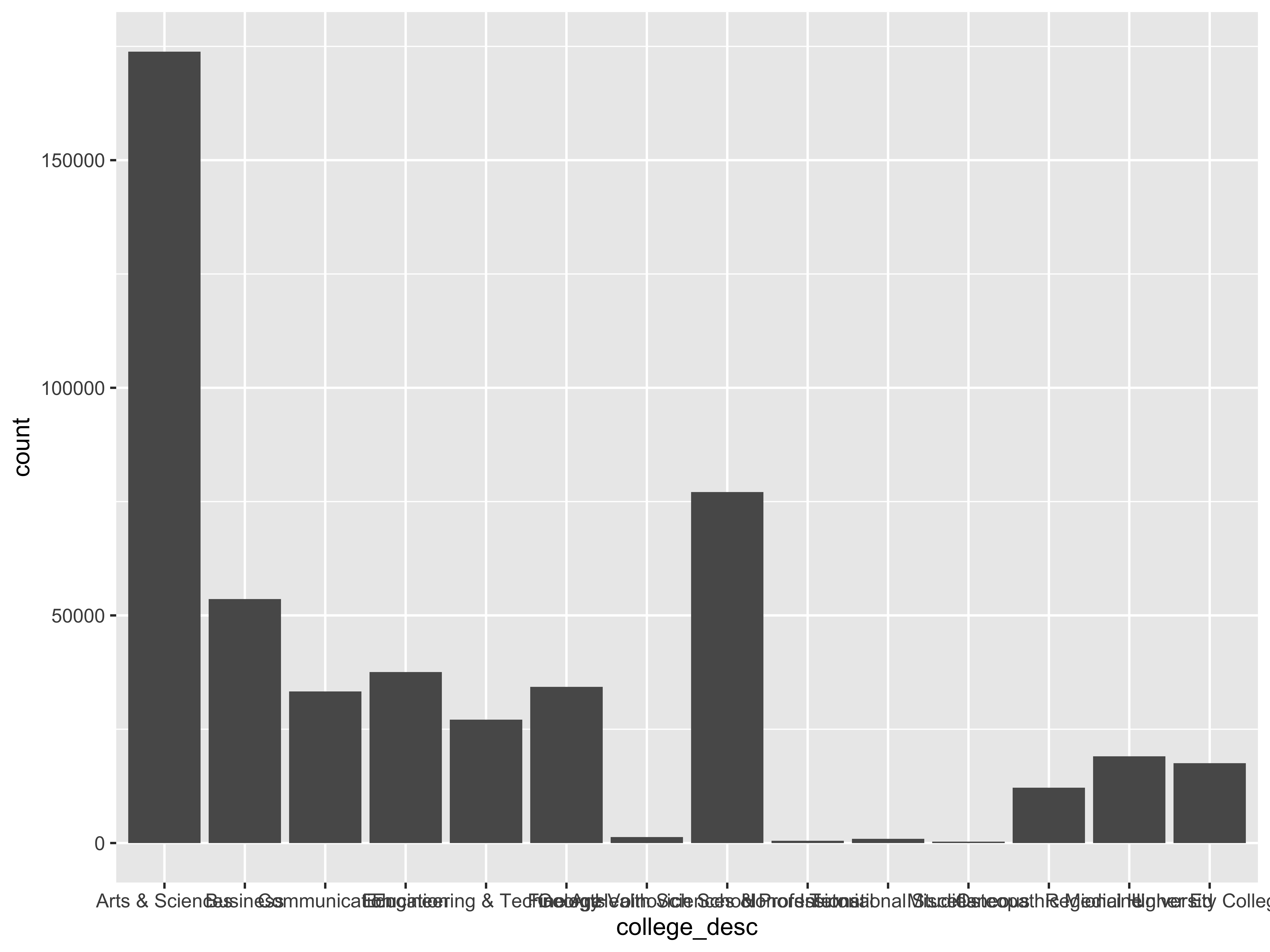
Notice that geom_bar() generates a bar-chart
The y-axis is mapping the frequency
We could do better of course, by customizing the labels for the x-axis and y-axis, adding a title and/or subtitle, a caption, maybe even coloring the bars
ggplot(data = my.df, aes(x = college_desc, fill = college_desc)) + geom_bar() + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research") + theme(legend.position = "bottom")
The x-axis labels are hard to read so we could flip the x- and y-axis
ggplot(data = my.df, aes(x = college_desc, fill = college_desc)) + geom_bar() + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research") + theme(legend.position = "bottom") + coord_flip()
How about ordering the colleges in terms of increasing/decreasing frequency?
library(forcats)my.df %>% group_by(college_desc) %>% summarise(frequency = n()) %>% ggplot(aes(x = fct_reorder(college_desc, frequency), y = frequency, fill = college_desc)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research") + theme(legend.position = "bottom") + coord_flip()Note how we are using the pipe operator %>% to do some calculations before seamlessly rolling into the plotting commands
fct_reorder(college_desc, frequency) is ordering the bars for us
library(forcats)my.df %>% group_by(college_desc) %>% summarise(frequency = n()) %>% ggplot(aes(x = fct_reorder(college_desc, -frequency), y = frequency, fill = college_desc)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research") + theme(legend.position = "bottom") + coord_flip()Note: fct_reorder(college_desc, -frequency)
We could still do better ... do we need a legend? No. How about better axis labels?
my.df %>% group_by(college_desc) %>% summarise(frequency = n()) %>% ggplot(aes(x = fct_reorder(college_desc, frequency), y = frequency, fill = college_desc)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research", x = "Number of Students", y = "College") + theme(legend.position = "hide") + coord_flip()
What if I want to look at enrollment numbers by sex?
my.df %>% filter(sex.f %in% c("Male", "Female")) %>% group_by(college_desc, sex.f) %>% summarise(frequency = n()) %>% ggplot(aes(x = fct_reorder(college_desc, frequency), y = frequency, fill = college_desc)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research", y = "Number of Students", x = "College") + theme(legend.position = "hide") + coord_flip() + facet_wrap(~ sex.f)
What if I want to show percentages instead of frequencies?
my.df %>% filter(sex.f %in% c("Male", "Female")) %>% group_by(college_desc, sex.f) %>% summarise(frequency = n()) %>% mutate(percent = (frequency / sum(frequency)) * 100) %>% ggplot(aes(x = fct_reorder(college_desc, percent), y = percent, fill = sex.f)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by Sex and College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research", y = "Percent", x = "College", fill = "") + theme(legend.position = "bottom") + coord_flip()
What if I want to store the summarized data as a data frame and then plot?
tab1 <- my.df %>% filter(sex.f %in% c("Male", "Female")) %>% group_by(college_desc, sex.f) %>% summarise(frequency = n()) %>% mutate(percent = (frequency / sum(frequency)) * 100) ggplot(data = tab1, aes(x = fct_reorder(college_desc, percent), y = percent, fill = sex.f)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by Sex and College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research", y = "Percent", x = "College", fill = "") + theme(legend.position = "bottom") + coord_flip()This approach is handy if you need to print or make available the table
What if we'd like to break out the preceding plot by students' rank?
my.df %>% filter(sex.f %in% c("Male", "Female")) %>% group_by(college_desc, rank_desc, sex.f) %>% summarise(frequency = n()) %>% mutate(percent = (frequency / sum(frequency)) * 100) %>% ggplot(aes(x = fct_reorder(college_desc, percent), y = percent, fill = sex.f)) + geom_bar(stat = "identity") + labs(title = "Distribution of Students by College", subtitle = "(Multiple Terms)", caption = "Source: Ohio University's Office of Institutional Research", y = "Percent", x = "College", fill = "Student's Sex at Birth") + theme(legend.position = "bottom") + coord_flip() + facet_wrap(~ rank_desc)
geom_line() and geom_point()
Let us calculate enrollments by college and term
tab2 <- my.df %>% group_by(term_code, college_desc) %>% summarise(frequency = n_distinct(anon_id)) ggplot() + geom_point(data = tab2, aes(x = term_code, y = frequency, group = college_desc, color = college_desc, size = frequency, shape = college_desc)) + geom_line(data = tab2, aes(x = term_code, y = frequency, group = college_desc, color = college_desc, linetype = college_desc)) + labs(x = "Term", y = "Number Enrolled", color = "")